Today, VMware announced vSphere+ and vSAN+, but what does that mean? Is it a new version?
In simple terms, both vSphere+ and vSAN+ are offerings of the existing vSphere and vSAN products. Think of it in term of purchasing a vehicle. You know what product you want, let’s say a Porsche, but you have the option of doing a capital expense (pay cash – excluding financing for simplicity), or you can lease. The product remains the same, which in this case is the Porsche vehicle you want to buy, but the offerings are different. You can make a purchase and pay the balance at time of exchange (capital expense) or you can lease it and pay as you.
Both vSphere+ and vSAN+ allows you to purchase the same vSphere and vSAN products you know and love, but now you can move to subscription and pay-as-you-grow. This is one of the differences between vSphere and vSphere+. Both products are deployed on-premises, managed from vCenter UI, so there is no change to the way you deploy, manage and configure vSphere and vSAN. However, there are additional advantages to both vSphere+ and vSAN+.

vSphere+ does not only allow you to move to subscription(OpEx) model, but it also allows your on-premises infrastructure to the cloud WITHOUT migrating any workloads, vCenters or ESXi hosts to the cloud. Your on-prem infrastructure securely becomes cloud connected.

Once connected, vSphere+ delivers those cloud benefits businesses seek and love to on-prem. Some of the benefits include:
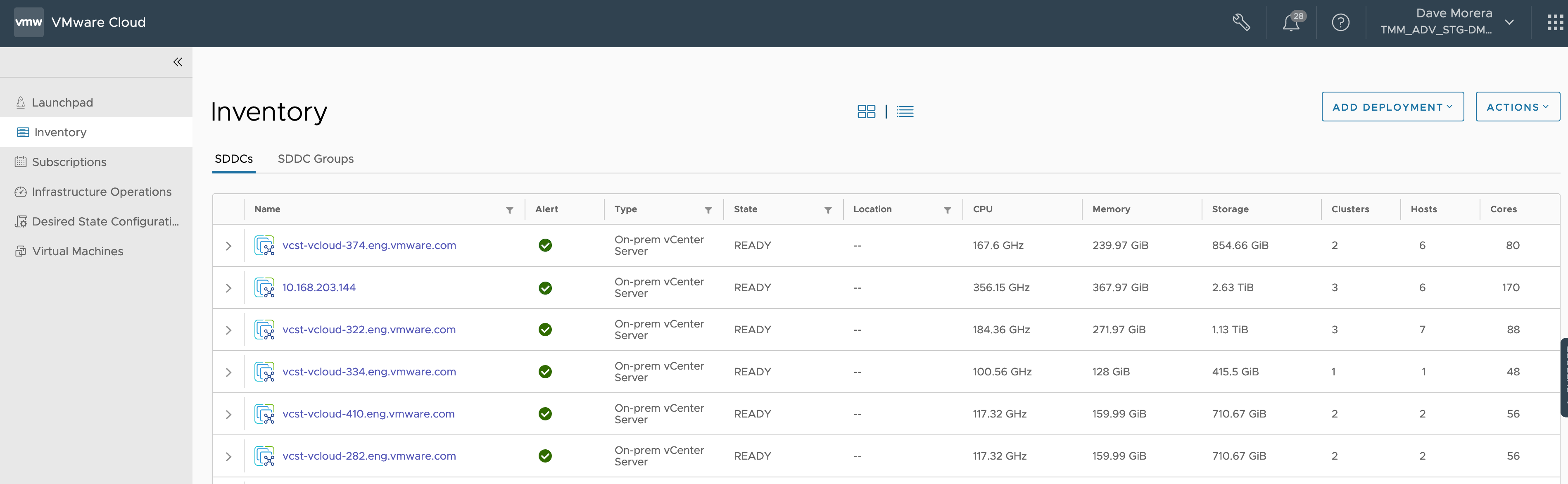
- Centralized Management for ALL vCenters without limit
- Simplified and Faster vCenter upgrades
- Centralized Operations view of alert, event and security posture of the global infrastructure regardless of the location
- Identify configuration drift among on-premises vCenters
- Move to subscription from a simple centralized cloud console
- Virtual Machine inventory and deployment to any vCenter while also being able to leverage vSAN datastores with vSAN+
These are just some of the features, and more coming soon.